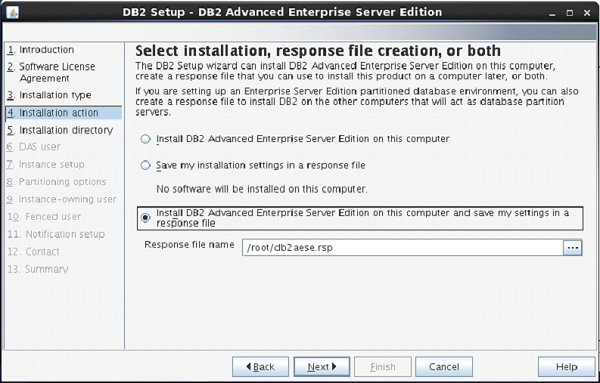
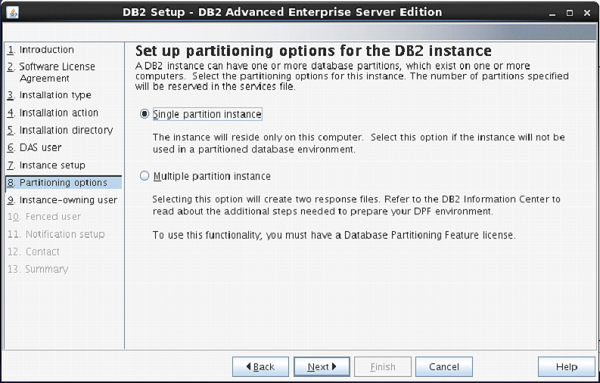
File and Storage Role is installed
by default in Windows Server 2012. This means you can create a file share with
a very minimal amount of work on a brand new server. To get started, as with
many things regarding Server 2012, open Server Manager.

From Server Manager, click on File
and Storage Services in the Server Manager sidebar. Then click on
Shares. From the Shares screen, click on the Shares drop-down list and
then click on New Share.

This will open the New Share Wizard.
From here, select a type of share. For the purposes of this article, we’ll
create a very basic SMB share, so click on “SMB Share – Quick.” Then click on
the Next button.

At the Share Location screen, I like
to click on “Type a custom path” and then click on the Browse button.

At the Select Folder screen, browse
to the folder you’d like to share out and then click on the Select Folder
button. Then click on Next back at the Share Location screen.

At the Share Name screen of the New
Share Wizard, enter the name you want users to see when accessing the share in
the Share Name field and the description (if any) that users will see in the
screen when connecting to the share. You’ll also see the local path used to
connect to that share on the server as well as the path that will be used to
connect remotely in this screen. Click Next once you’ve entered the
information.

At the Other Settings screen, you
have 4 options (checkboxes):
- Enable Access Based Enumeration: If you have Mac clients this is often a bad idea. This feature ends up not showing people objects they don’t have access to. It’s great in a purely Windows environment, thought.
- Allow Caching of Share: Allows Windows clients to right-click on a share and choose to cache it.
- Enable Branch Cache on the File Server: Allows a computer in a branch office to act as a Branch Cache server/workgroup server.
- Encrypt data access: Encrypts traffic to the share.
Most of these options are pretty
irrelevant to the Mac and Linux, but can be helpful in purely Windows environments,
especially if you need additional security or want your users caching data from
the share. Once you’ve chosen the options that best work for you, click Next.

At the Permissions screen, choose
who has access to connect to the share. Note that controlling permissions to
access objects from inside the share is done separately through the share and
this option is just used to configure who can mount/map to the share. Click
Next once only the users you want to access the share have the appropriate
level of access.

At the Confirmation screen, verify
that all the settings for the share are correct and then click on the Create.

Once the share is created, click on
Close button.

Then connect to the share and verify
that the settings are as appropriate. Once done, create the subdirectories for
the root level and configure permissions as appropriate.