DB2 - Server Installation
Introduction
You can download the DB2 Server trial version or purchase the product license from www.ibm.com. There are two separate DB2 servers available for downloading, depending upon the size of operating system, on which it is intended to execute. For example, if you want to download a DB2 server for 32bit Linux or UNIX operating system, then you need to download a 32 bit DB2 server. The same applies for 64bit DB2 server.
Hardware requirements
Processor : Minimum Core 2Duo
Ram : 1GB minimum
Hard disk : 30GB minimum
Software requirements
Before installing the DB2 server, your system needs to get ready with the required software on it. For Linux, you need to install “libstdc++6.0”.
Checking system compatibility
Before installing DB2 Server, you need to verify if your system is compatible with the DB2 server. For confirming the compatibility, you need to call 'db2prereqcheck' command on command console.
Installing DB2 on Linux operating system
Open the Terminal and set the db2 installation image folder path on console using “CD <DB2 installation folder>” command. Then type “./db2prereqcheck” command, which confirms the compatibility of your system with DB2 server.
./db2prereqcheck
Figure-1 shows the compatibility requirements of Linux operating system and hardware system.
Follow the given steps for installing DB2 on your Linux system:
This process will start execution of DB2 server setup.
Type “./db2setup” and press Enter on root terminal to start setup process of DB2 Server.
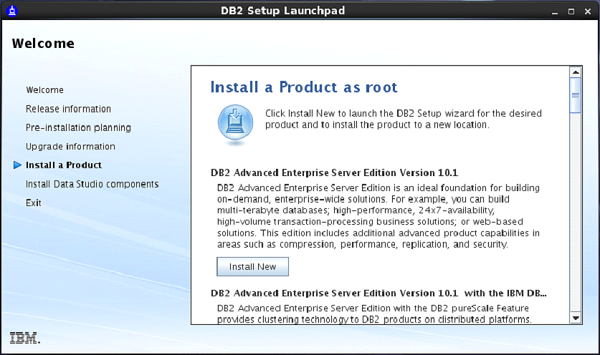
On doing so, the “Set up Launch Pad” screen appears. [Figure-2]
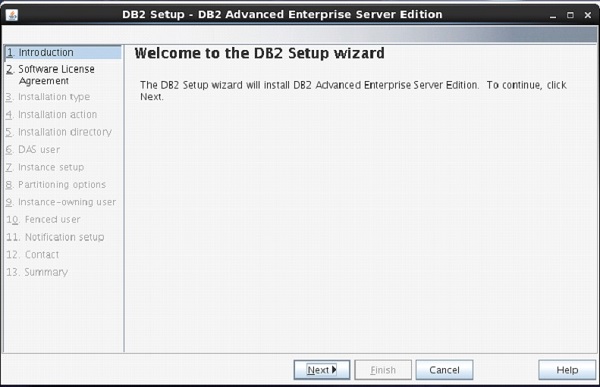
On Setup Launch pad page, select “Install a Product” option from left side menu. Select option “DB2 Advanced Enterprise Server Edition”. Select “Install New” Button.
A new frame appears with name “DB2 setup wizard”. Click “Next”. [Figure-3]
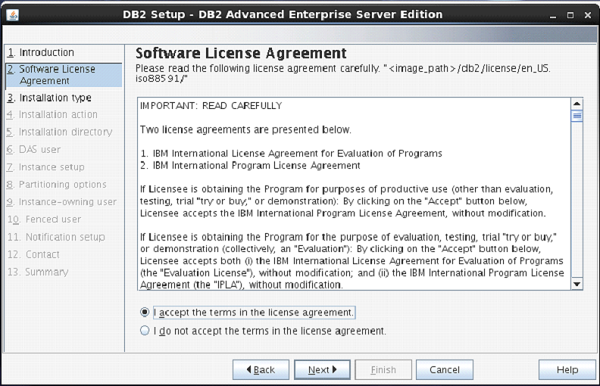
The next screen appears with DB2 license agreement. Select “I accept the terms…” Click “Next”. [Figure-4]
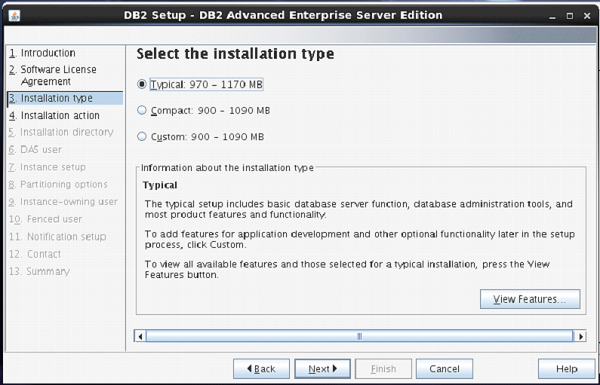
Next screen comes up with offer of Installation type, which is set to “Typical” by default.
Keep the same selection. Click “Next”. [Figure-5]
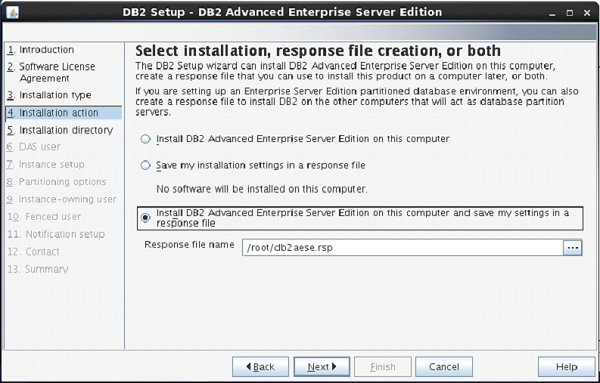
The next screen appears with installation action.
Select “Install DB2 Advanced Enterprise Server Edition…”
Click “Next”. [Figure-6]
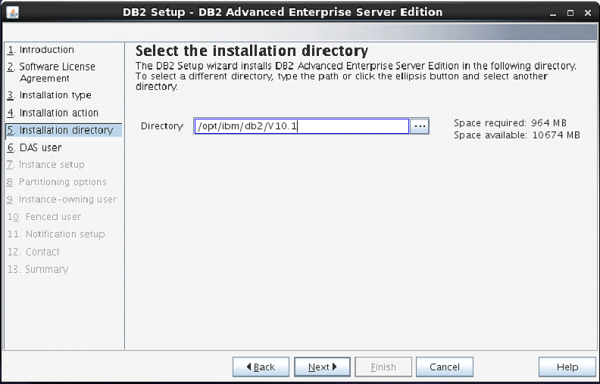
On the next screen, the setup program asks for selection of installation directory.
Keep the default and click “Next”.
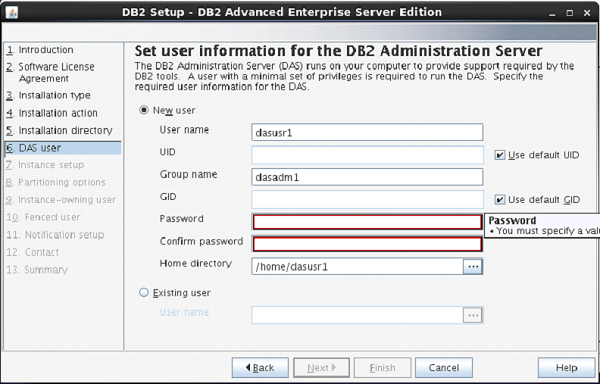
The next screen comes up with the user authentication. Enter your password for “dasusr1” user.
(Your password can be identical to username so that it is convenient to remember.)
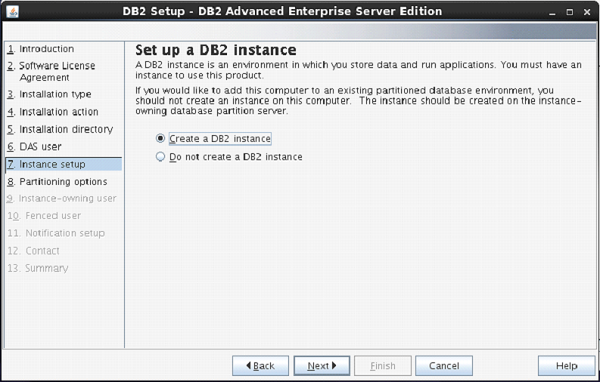
On the following screen, the setup asks you for creation of DB2 Server Instance.
Here, it is creating a DB2 instance with name “db2inst1”.
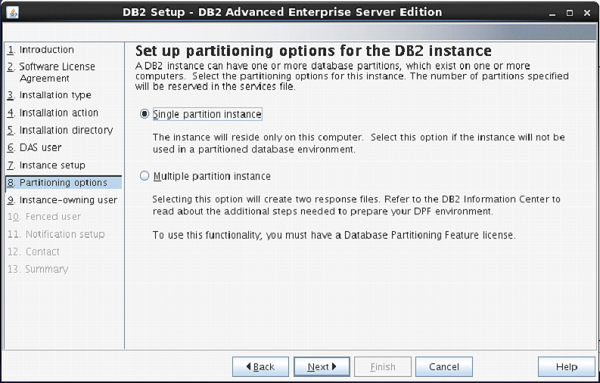
The next screen asks you the number of partitions you require for your default instance.
You have a choice of “single or Multiple” partitions.
Select “single partition instance”. Click “next”.
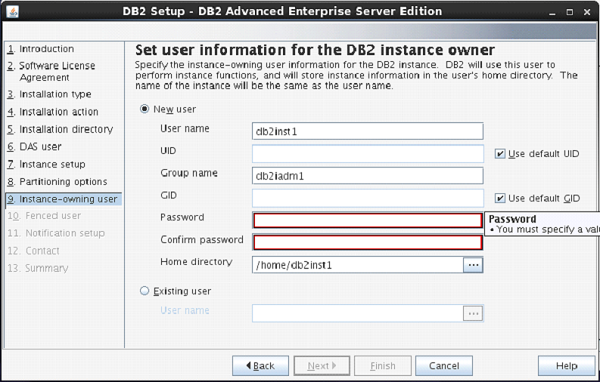
On the next screen, the setup asks you for authentication for DB2 instance being created.
Here, by default username is created as “db2inst1”. You can enter password same as username.
Click “Next”.
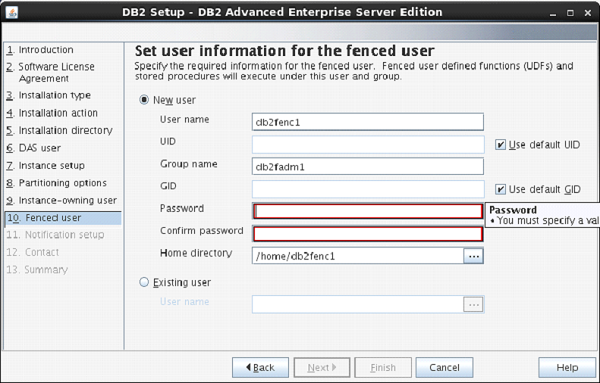
On the next screen, the setup asks to enter authentication information for “db2fenc” user.
Here, you can enter password same as username.
Click “Next”.
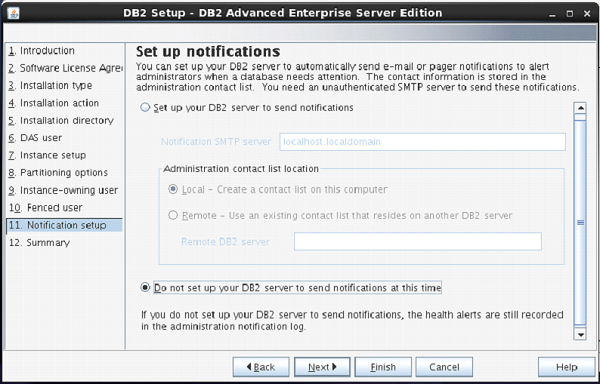
On the next screen, you can select “Do not setup your db2 server to send notifications at this time” option.
Click ”Next”.
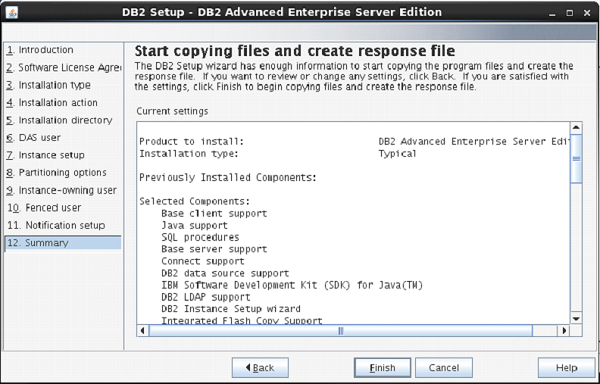
The next screen shows you the information about db2 setup.
Click “Finish”.
The DB2 Installation procedure is complete at this stage.
Verifying DB2 installation
You need to verify the installation of DB2 server for its usefulness. On completing the DB2 Server installation, logout from current user mode and login to “db2inst1” user. In “db2inst1” user environment, you can open terminal and execute the following commands to verify if your db2 product is installed properly or not.
db2level
This command shows the current version and service level of the installed DB2 product for current instance.
Syntax:
db2level
Example:
db2level
Output:
DB21085I Instance "db2inst2" uses "64" bits
And DB2 code release "SQL10010" with level
identifier "0201010E". Informational tokens
are "DB2 v10.1.0.0", "s120403",
"LINUXAMD64101", and Fix Pack "0".
Product is installed at "/home/db2inst2/sqllib".
db2licm
This command shows all the license related information of our DB2 Product.
Syntax:
db2licm <parameter>
Example:
db2licm -l
Output:
Product name: "DB2 Advanced Enterprise Server Edition"
License type: "Trial"
Expiry date: "10/02/2014"
Product identifier: "db2aese"
Version information: "10.1"
Product name: "DB2 Connect Server"
License type: "Trial"
Expiry date: "10/02/2014"
Product identifier: "db2consv"
Version information: "10.1"
Command Line Processor (CLP)
The CLP can be started in one of the three modes:
Command mode: In this mode, each command and SQL statement must be prefixed by “db2”. For example, query “db2 activate database sample”.
Interactive input mode: you can launch this mode by using the “db2” command. Here, you can pass SQL statements without prefix. For example, “activate database sample”.
- Batch mode: Here, you need to create a script file, which contains all SQL queries of requirements and save the file with “.db2” extension. You can call this in command line using syntax “db2 –tf <filename.db2>”.